Active learning: iteratively expanding the training set¶
Active learning (AL), also called sequential training, describes iteratively adding training samples to a surrogate model.
The new samples can be chosen in an explorative manner or by exploiting available data and properties of the surrogate.
The relevant functions are contained in the class bayesvalidrox.surrogate_models.sequential_design.SequentialDesign and bayesvalidrox.surrogate_models.exploration.Exploration.
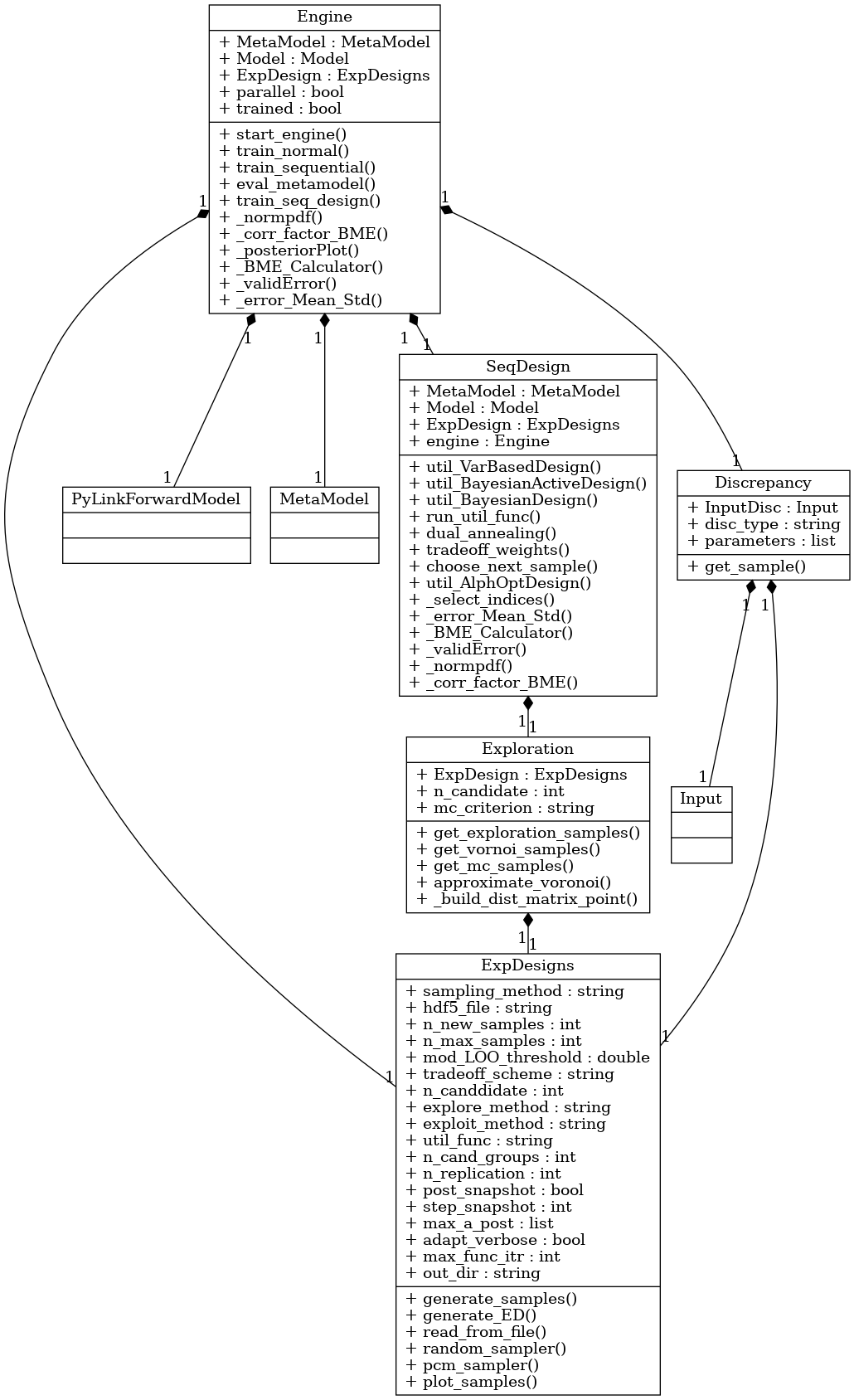
In BayesValidRox AL is realized by additional properties of the bayesvalidrox.surrogate_models.exp_designs.ExpDesigns and bayesvalidrox.surrogate_models.engine.Engine classes without any changes to the surrogate model.
Exploration, exploitation and tradeoff¶
How the new samples are chosen is characterized by three things: the exploration method, the exploitation method, and the tradeoff scheme.
All three of these are set in the bayesvalidrox.surrogate_models.exp_designs.ExpDesigns class.
Exploration¶
The exploration method describes how the proposed canditate samples are generated. Each canditate is assigned an exploration score.
Voronoi, Random, Latin-hypercube¶
These three options are based on space-filling design. The name describes the sampling type which is used for the candidate samples. The exploration scores are assigned based on distance to the existing training samples.
LOOCV¶
The candidate samples are generated randomly in the input space. The candidate scores are calculated based on the loocv-error that is estimated during surrogate training. For this a GPE-based error model is trained on the training samples and corresponding loocv error. The scores are set to be the evaluation of the error model on the exploration candidates. This is equivalent to choosing the candidate with the highest expected error.
Warning
loocv exploration only applicable to (a)PCE training at the moment.
Dual annealing¶
Uses scipy’s scipy.opt.dual_annealing to find a global minimum of the given function.
If this is used, then the tradeoff is automatically set to exploit_only.
Exploitation¶
The exploitation methods make use of available data, or properties of the model, to choose the next sample.
The candidates are taken based on the exploration scheme, and then assigned an exploitation score.
Exploitation can be set to BayesActDesign, VarOptDesign or Alphabetic.
For each exploitation type, a utility function can be set.
BayesActDesign¶
Uses Bayesian inference and information-theoretic criteria to select surrogate training points. This performs Bayesian Inference using rejection sampling on the surrogate predictive distribution.
The possible optimization criteria/utility function are:
DKL(Kullback-Leibler divergence): Maximizes the expected information gain when updating from prior to posterior after observing the candidate point.IE(Information entropy): Selects candidates that minimize the entropy of the posterior distribution.BME(Bayesian model evidence): maximizes the marginal likelihood of the model given the candidate point.DIC(Deviance Information Criterion): Bayesian model selection metric combining model fit and an estimate of model complexity via the effective number of parameters.BayesRiskDPP(D-posterior precision)APP(A-posterior precision)
Warning
BayesActDesign can only be used if observation data is available, and with surrogates that return predicted standard deviations.
VarOptDesign¶
With VarOptDesign we choose samples that are expected to reduce the uncertainty associated with the overall surrogate prediction. There are two possible options for VarOptDesign:
ALM(Active Learning MacKay): Selects points where the surrogate model’s predictive variance is largest.EIGF(Expected Improvement for Global Fit): Selects points where the prediction error (vs. nearest observed data) plus the variance is largest.MI(Mutual Information): Selects candidate points that maximize mutual information between the new sample and the unobservedALC(Active Learning Cohn): Selects candidate points that minimize the average predictive variance across a set of Monte Carlo evaluation points. In our implementation, we minimize the expected variance of adding a given candidate by maximizing the reduction in variance when adding a given candidate.
Warning
VarOptDesign can only be used with surrogates that return predicted standard deviations.
Alphabetic¶
There are three possible options for Alphabetic optimal design:
D-opt: maximizes the determinant of the PCE information matrixA-opt: minimizes the average variance of the parameter estimatesK-opt: minimizes condition number of PCE information matrix
Warning
Alphabetic only possible for PCE-type surrogates.
Tradeoff¶
The tradeoff schemes describe how much weight is given to the exploration and exploitation schemes.
explore_only: The next samples are chosen in a fully space-filling way, no exploitation is performed.Exploit_only: The next samples are chosen only based on the exploitation results.Equal: The exploration and exploitation scores are assigned equal weights in the final decision.Epsilon-decreasing: Start with more exploration and increase the influence of exploitation along the way with an exponential decay function.Adaptive: Starts with an equal split, then adapts the weights based on the difference between the last two iterations.
Example¶
We take the engine from Training surrogate models and change the settings to perform sequential training.
This mainly changes the experimental design.
For this example we start with the 10 initial samples from Training surrogate models and increase them iteratively to the number of samples given in n_max_samples.
The parameter n_new_samples sets the number of new samples that are chosen in each iteration.
>>> exp_design.n_max_samples = 14
>>> exp_design.n_new_samples = 1
Here we set the tradeoff_scheme so that all samples are chosen based on the exploration scheme.
>>> exp_design.tradeoff_scheme = 'explore_only'
As the proposed samples come from the exploration method, we still need to define this.
>>> exp_design.explore_method = 'random'
If we want to use exploitation, we could use a variance-based method, as no data is given.
>>> exp_design.exploit_method = 'VarOptDesign'
>>> exp_design.util_func = 'EIGF'
>>> exp_design.n_cand_groups = 4
Once all properties are set, we can assemble the engine and start it.
This time we use train_sequential.
>>> engine = Engine(meta_model, model, exp_design)
>>> engine.train_sequential()